The project builds criterion-wise supervision for real 3D assets,
validates its alignment with human judgment, and distills it into an
efficient 3D evaluator.
01 / Motivation
Real 3D assets need a different quality target.
Most existing 3D-QA benchmarks start from a small set of clean
objects and inject synthetic degradations such as noise,
compression, or downsampling. That setup measures distortion
severity, but it does not fully capture naturally occurring
artifacts in diverse asset repositories.
Asset quality is shaped by geometry, texture, material,
plausibility, and visible artifacts.
Human preference matters for evaluation, curation, and
downstream generation pipelines.
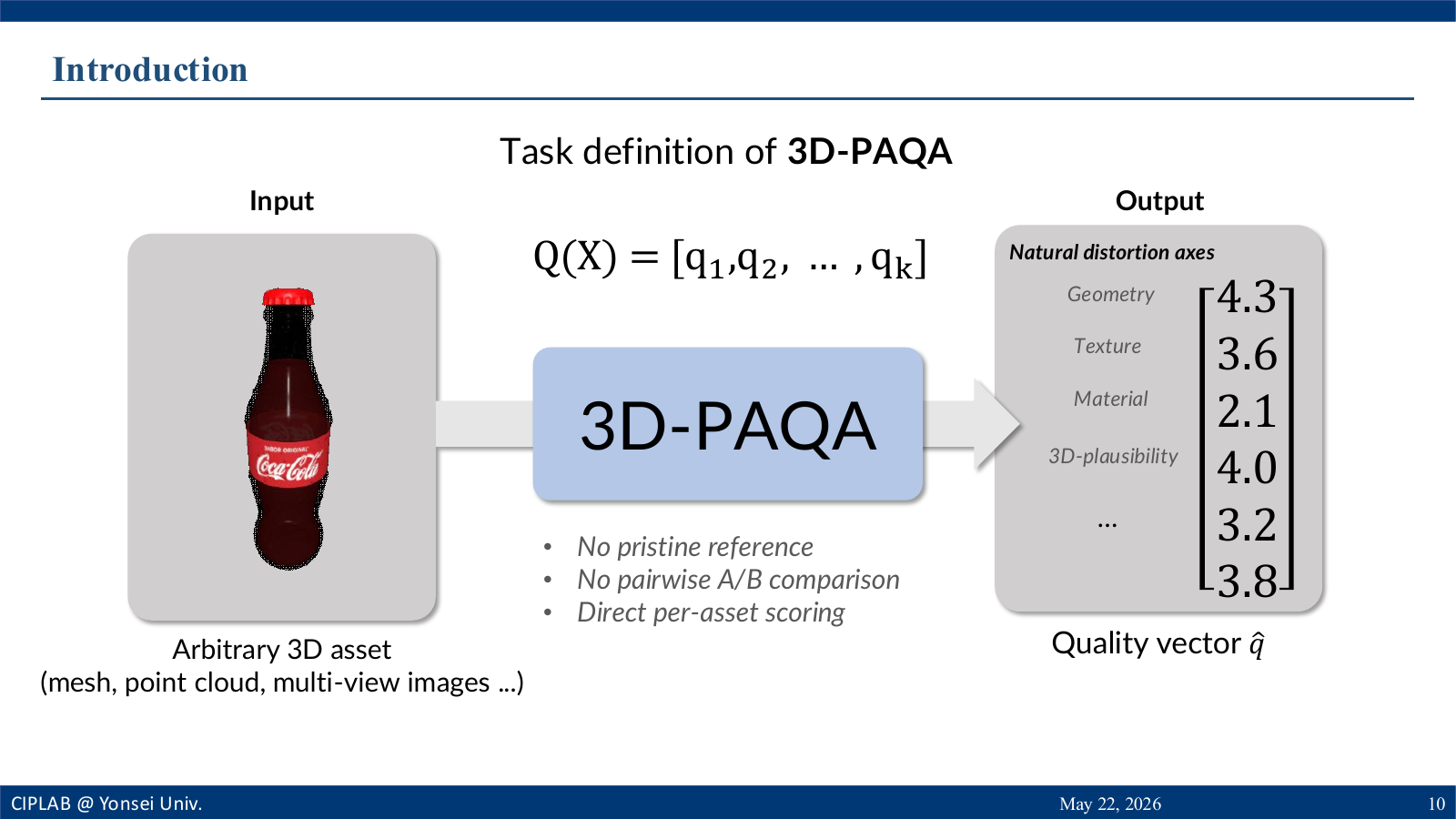
3D-PAQA maps an arbitrary 3D asset to a criterion-wise quality
vector.
02 / Task
Direct per-asset scoring replaces reference dependence.
The task estimates a quality vector for an arbitrary 3D asset.
It does not require a pristine reference, an artificial
distortion operator, or pairwise A/B aggregation for every
target asset.
The six axes cover holistic preference, plausibility, artifacts,
and component-level geometry, texture, and material quality.
Holistic
Preference
Plausibility
Artifacts
Components
Geometry
Texture
Material
Output
A quality vector that can diagnose where an asset is strong or
weak.
03 / Annotation
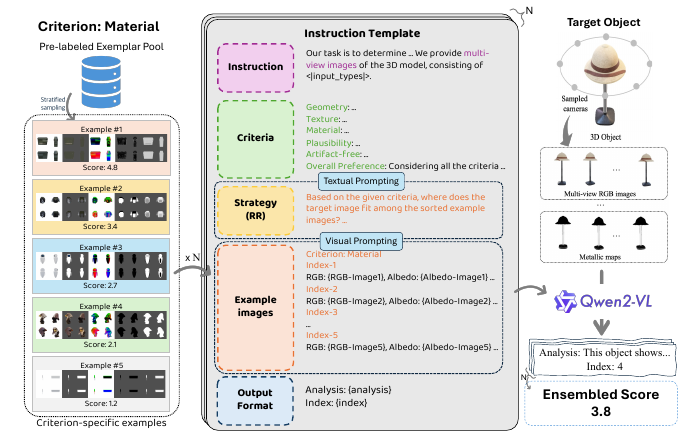
Exemplar anchors ground subjective judgments.
The large-scale annotation pipeline injects human preference
through stratified exemplar anchors. Each target is shown with
multi-view evidence and quality-spanning references so the MLLM
judgment is grounded by examples.
Relative Ranking positions the target among anchored quality
levels.
Repeated anchor sampling and ensembling reduce anchor-specific
bias.
The annotation process combines visual prompts, criteria
instructions, and relative ranking outputs.
04 / Dataset
The supervision scales across assets and criteria.
3D-PAQA gathers preference-aligned annotations for over 260K
Objaverse-based assets across ten semantic domains. The criteria
separate overall perception from component-level weaknesses.
Natural artifacts instead of hand-injected distortions.
Six quality signals for richer diagnosis than one global
score.
MLLM-aligned labels designed for training and analysis.
Dataset overview from the project presentation.
05 / Evaluator
A compact 3D model distills the quality signal.
The project trains a lightweight evaluator on 3D-PAQA
annotations. A Point Transformer-v3 backbone predicts
criterion-wise quality directly from sampled 3D features.
Inputs include point cloud signals such as RGB, normals, and
PBR attributes.
The evaluator has 33M parameters, roughly 0.046% of the 72B
teacher scale.
Preference-aligned supervision remains useful after
distillation.
The distilled evaluator predicts the same criterion-wise quality
structure from 3D features.
06 / Evidence
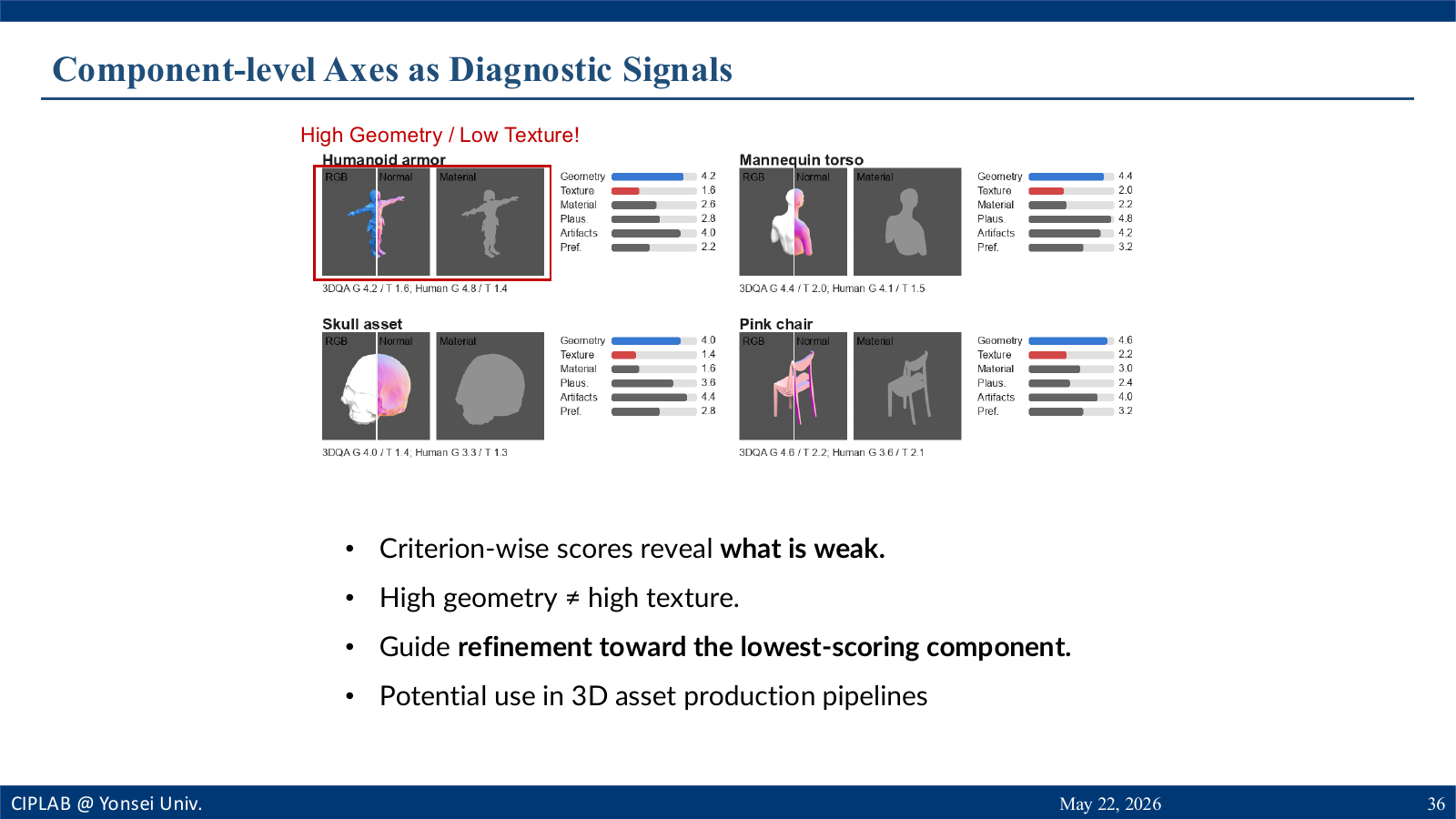
Criterion-wise scores become diagnostic signals.
The analysis shows that 3D-PAQA annotations align with human
preferences and capture perceptual quality beyond simple
geometry complexity. Component-level axes also reveal localized
failures.
72B relative ranking is adopted for preference-aligned
supervision.
The compact evaluator achieves strong human alignment on
overall preference.
High geometry quality does not guarantee strong texture or
material quality.
Lower-scoring criteria point to the asset component that needs
attention.
Applications and current limits
The quality signal can support evaluation, repository curation, and
future quality-guided generation or refinement. The current work
builds the supervision and evaluator foundation; full downstream
validation, transfer to AI-generated assets, and
application-specific model ranking remain future work.